
Modelling Multigraphism: The Digital Representation of Multiple Scripts and Alphabets
Digital approaches to palaeography – the study of historical or ancient handwriting – have received significant attention in recent years. Projects like ORIFLAMMS (Stutzmann, 2016) and DigiPal (Brookes, 2015) have focussed on this, as well as projects aimed more at the book or written object in general such as HisDoc and Diva DIA, work on the Cairo Genizah (e.g. Wolf et al., 2011), work at the Centre for the Study of Manuscript Cultures (CSMC) in Hamburg; and many more. Although taking different approaches and addressing different aspects of palaeography, these projects have all made significant and important advances. However, relatively few have addressed explicit semantic modelling of handwriting itself. One such model was developed for the DigiPal project (Stokes, 2012) and has since been implemented in open-access and freely-available software called Archetype (2017). The model was developed initially for the Latin alphabet, but it has proven to be much more versatile than anticipated, with application to Hebrew and decoration (Brookes et al., 2015), bilingual Greek-Latin inscriptions, and experiments with Chinese, Cuneiform, Mayan, and others (see Figure 1 and Figure 2).
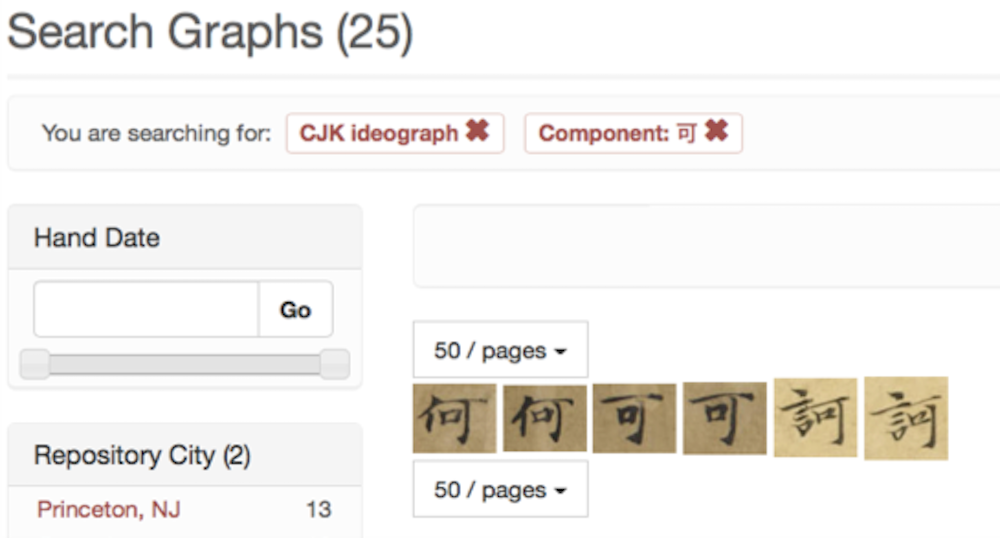
Figure 1: Archetype applied to Chinese script, showing search results for characters (graphs) containing the component 可
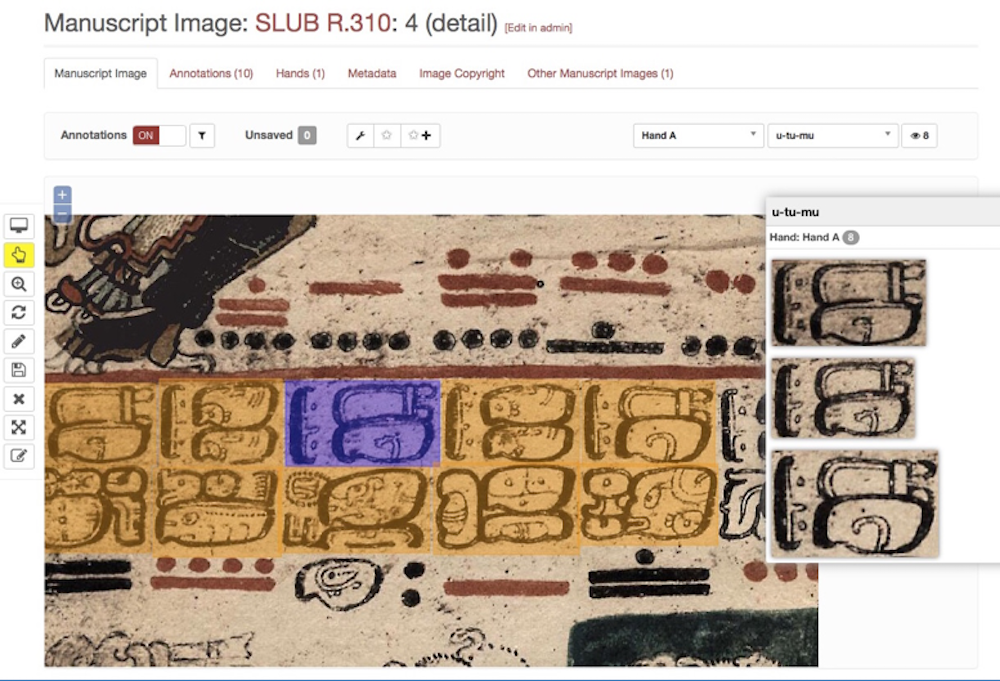
Figure 2: Demonstration of Archetype applied to Mayan hieroglyphics
Although applied successfully to different scripts, the DigiPal model (like most palaeographical method) assumes a homogeneous corpus comprising samples of the same alphabet and writing-style. Although convenient, this homogeneity is in fact very limiting, as throughout history many, perhaps even most, societies employed a range of different writing styles and systems. In Western Europe, for example, the best-known example is probably the Gothic script-system, comprising
Textura,
cursiva and so on; but similar patterns can be observed elsewhere in Hebrew, Arabic, Chinese, Tibetan and beyond. Furthermore, different alphabets or writing systems were often used together. Egyptian scribes use hieroglyphic, Hieratic and Demotic contemporaneously; Greek and Latin inscriptions are found across much of the Roman Empire, sometimes with third languages and alphabets; the Dunhuang materials contain a wide range of languages and scripts including Chinese, Tibetan, Sanskrit, Arabic and Sogdian; materials in four writing-systems survive from medieval Sicily; and so on. All of this suggests very strongly that people often – perhaps usually – could and did write in different alphabets or writing-systems. Identifying such cases would give us much important information about areas like education (how many Arab scribes also learned Hebrew?), cultural influence (were Sogdian annotations written at the same time and place as the main text in Chinese?) and so on. However, this requires an approach that allows for comparison across different scripts, discussion of which has really only just begun in both «digital» and «non-digital» palaeography (Stokes, 2017).
In principle, the DigiPal model provides such a framework. It specifies that characters are made up of components, defined as structural elements which recur across different letters (such as the ascenders in
b,
h,
l and so on: Stokes, 2012). If one can map between components of different writing-systems then it is relatively easy to search for graphs (i.e. instances of letters written on the page) which share those components, and this allows for comparison. A proof-of-concept is illustrated in Figure 3, where six instances of the Archetype system are searched simultaneously via the software’s web API; a further example is given by Stokes (2017).

Figure 3: Screenshot from proof-of-concept cross search for example letters (graphs) with ascenders
However, multigraphic contexts require revising some basic assumptions of the model. For instance, DigiPal (and much palaeographical discussion) assumes that «etically» same is also «emically» same: that things that look the same mean the same.
H and
H look identical and therefore are normally assumed to represent the same letter: this is normally valid and indeed essential for communication in a monographic context. However, it may not hold in general: if we write
HELLO and I
HΣOΥΣ then it becomes clear that the first is the Latin capital H (Unicode U+0048) and the second a Greek capital Eta (Unicode U+0397: cf. Bugarski, 1993). In context one can categorise these as separate characters, but a user searching the database for palaeographically comparable forms would presumably want to find both. Similar are apparently unambiguous characters used for different functions, perhaps deliberately to echo a different writing system. For example, in «pseudo-fonts» like GRΣΣK, the linguistic context shows that the two central letters function as the English grapheme E, but they are represented by the Greek capital Sigma. Comparable examples are widespread, such as the use of Greek letters in the Latin text of the ninth-century Lindisfarne Gospels illustrated in Figure 4. In a monographic context this could be addressed as grapheme E with allograph «sigmoid» or something similar, but in a multigraphic context a palaeographer would presumably want to be able to find examples of both capital Sigma and «sigmoid» E with a single search and without necessarily anticipating the coincidence of forms in advance.
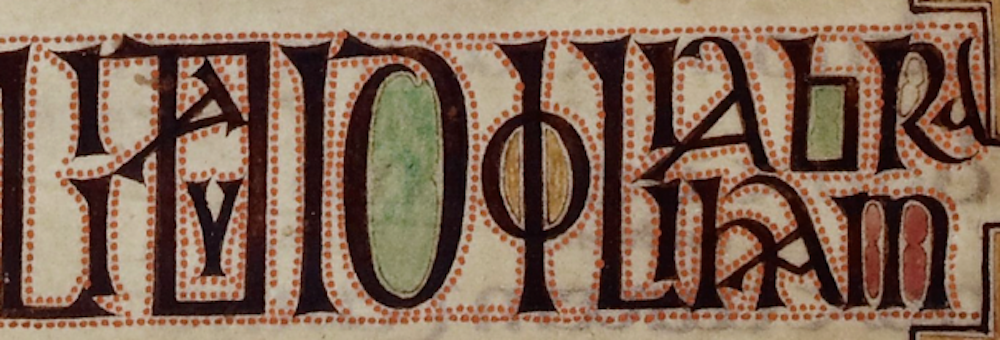
Figure 4: Detail from the Lindisfarne Gospels (London, British Library, Cotton Nero D.iv), showing use of Greek letters for writing Latin
In order to address this, some changes to the DigiPal model are proposed. The first is to change the central hierarchy of Character-Allograph-Idiograph-Graph presented by Stokes (2012), separating the linguistic/emic from the graphic/etic in a many-to-many relationship as shown in Figure 5 and Figure 6. This allows users to search by form, component or linguistic function.
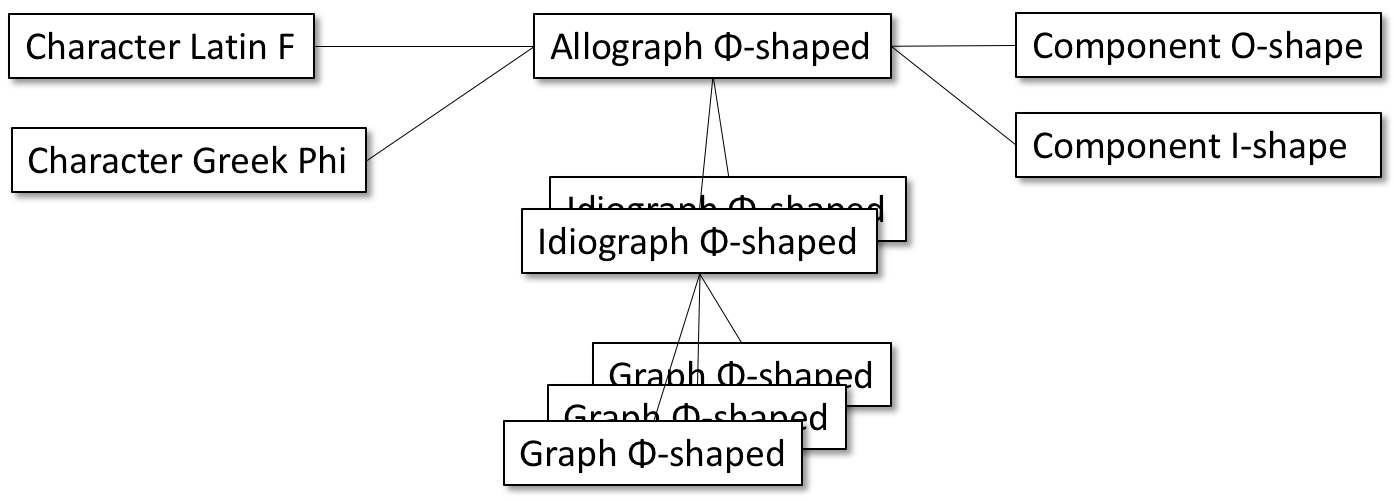 Figure 6: Example of the model applied to the form Φ used for Latin
Figure 6: Example of the model applied to the form Φ used for LatinF as shown in Figure 4
A further more practical change is to add sub-components. The use of components works well for alphabets and abugidas but much less so for more ideographic or hieroglyphic writing systems. In these cases, characters are made up of components which can themselves be further characters which contain further components, and so on. With sub-components, a component may be a discrete entity in its own right, or it may be made up of a set of further components. One might then describe the Korean glyph 곥 as a character having ㅈ as a component which has フ as a sub-component; this would allow retrieval of all instances of any graphs (character blocks) containing ㅈ, or idiographs containing フ, and so on (cf. Stokes, 2014). The same approach can be used for writing systems with subscript letters or character stacks, such as Myanmar or Tibetan (e.g. the second element in བསྒྲུབས་ which comprises four distinct characters: Flynn, 2015), or even ligatures and conjoined letters such as ſt. This then allows searching for more complex components that reoccur across writing systems, such as the Korean sub-component ㅈ (U+110C) which also appears in Japanese
katakana as a distinct character (ス, U+30B9) and as a sub-component in numerous Chinese ideographs.
One limitation of this model is the lack of linguistic context. DigiPal treated characters as distinct entities with no direct relationship between each other, but in practice letters normally appear in a broader linguistic context, namely the text, and this becomes essential in a multigraphic environment. Archetype goes some way towards addressing this, as it allows for including the text on an image, and the text itself can be marked up in XML and then linked in turn to sections of the image (Figure 7 and Figure 8). From this it is relatively trivial to detect the section of text in which a given graph is found, and if the XML markup specifies the language then this would allow one to find (for example) occurrences of a given grapheme or allograph within a specific linguistic context without needing to specify the language of each individual graph.

Figure 7: Screenshot of Archetype used to provide Hebrew transcription and English translation linked to manuscript image, courtesy of Stewart Brookes

Figure 8: Screenshot of Archetype implemented for the Models of Authority project, showing text and image isolated by XML markup (here for
salutatio clauses in medieval charters)
These extensions and changes to the model are not sufficient in themselves to fully address the challenges raised here. For instance, they still assume that different scripts can be reduced to common «atomic» units but it is not clear that this always holds, particularly for scripts that have entirely different genealogies such as Chinese and Sogdian, or when different writing implements and different directionality of script is involved (but see Stirnemann and Oszlowy-Schlanger, 2012). It also assumes that researchers can agree on what these «atoms» might be, and in principle link between them using the Semantic Web or similar. In some cases these units are evident, such as ascenders or descenders in many scripts, or the radical in Chinese and so on, but as Petrucci in particular has pointed out different scholarly viewpoints will necessarily produce different descriptions, and each of these different views is potentially valid and important (2001: 70–1), but it is not evident that they can necessarily be compared. This problem that extends well beyond the present discussion to encompass data interchange in general, though in practice it may be that if different scholars have such different approaches then perhaps uniting them is not meaningful, and an «ecosystem» of alternative viewpoints may be more appropriate.
Nevertheless, work to date suggests that the approach described here can provide a useful entry into the problems of multigraphism, particularly when combined with further refinements such as the distinction between components of allographs as envisaged by the scribe «in mind’s eye» and traces of graphs actually executed on the page, as well as the ability to compare «essential elements» like components as well as «elements of style» in DigiPal’s Features (Stokes, 2017 and Parkes, 2008). By building further in this direction, and most likely also adding machine vision and other approaches to searching, it seems likely that good further progress can be made.
Appendix A
- Brezina, D. (2013) Balkan Sans.
Typographica,
http://typographica.org/typeface-reviews/balkan-sans/ (accessed 26 November 2017). - Brookes, S.J. et al. (2015). The DigiPal Project for European scripts and decorations. In Conti, A., O. da Rold and P. Shaw (eds),
Writing Europe 500–1450: Texts and Contexts.
Essays and Studies n.s. 68: 25–58 - Bugarski, R. (1993). Graphic relativity and linguistic constructs. In Scholes, R.J. (ed.),
Literacy and Language Analysis. Hillsdale, NJ: Erlbaum, pp. 5–18. - Centre for the Study of Manuscript Cultures. University of Hamburg,
https://www.manuscript-cultures.uni-hamburg.de/index_e.html (accessed 26 November 2017). - DigiPal. (2010–14).
Digital Resource and Database of Palaeography, Manuscript Studies and Diplomatic. London: King’s College,
http://www.digipal.eu (accessed 26 November 2017). - Diva DIA. University of Fribourg,
https://diuf.unifr.ch/main/hisdoc/divadia (accessed 26 November 2017). - Flynn, C. (2015). Encoding model of the Tibetan script in the UCS.
The Tibetan and Himalayan Library,
http://www.thlib.org/tools/#wiki=/access/wiki/site/26a34146-33a6-48ce-001e-f16ce7908a6a/encoding%20model%20of%20the%20tibetan%20script%20in%20the%20ucs.html (accessed 26 November 2017). - HisDoc. University of Fribourg,
https://diuf.unifr.ch/main/hisdoc/hisdoc2 (accessed 26 November 2017). - Models of Authority (2017): Scottish Charters and the Emergence of Government 1100–1250. London: King’s College,
https://www.modelsofauthority.ac.uk (accessed 24 April 2018). - Parkes, M.B. (2008).
Their Hands Before Our Eyes: A Closer Look at Scribes. Ashgate: Aldershot. - Petrucci, A. (2001).
La descrizione del manoscritto: storia, problem, modelli. 2
nd ed. Roma: Carroci. - Stirnemann, P. and Olszowy-Schlanger, J. (2008). The Twelfth-century trilingual psalter in Leiden.
Scripta 1, pp. 103–112. - Stokes, P.A. (2012). Modeling medieval handwriting: A new approach to digital palaeography.
Digital Humanities 2012: Book of Abstracts. Hamburg: University of Hamburg, pp. 382–5,
http://www.dh2012.uni-hamburg.de/conference/programme/abstracts/modeling-medieval-handwriting-a-new-approach-to-digital-palaeography (accessed 24 April 2018). - Stokes, P.A. (2014). Describing handwriting, part VII: Chinese (Han) script.
DigiPal: Digital Resource and Database of Palaeography, Manuscript Studies and Diplomatic. London: King’s College,
http://www.digipal.eu/blog/describing-handwriting-part-vii-chinese-han-script/ (accessed 24 April 2018). - Stokes, P.A. et al. (2016). The Models of Authority Project: Extending the DigiPal Framework for Script and Decoration.
Digital Humanities 2016: Conference Abstracts. Krakow: pp. 896-99,
http://dh2016.adho.org/abstracts/387 (accessed 24 April 2018). - Stokes, P.A. (2017). Scribal attribution across multiple scripts: A digitally-aided approach.
Speculum 92: S65–85.
doi:10.1086/693968 (accessed 24 April 2018). - Stutzmann, D. (2016)
Compte-rendu de fin de projet: ORIFLAMMS : Programme Corpus, données et outils,
https://f.hypotheses.org/wp-content/blogs.dir/1267/files/2017/04/Oriflamms-Compte-rendu-final.pdf (accessed 24 April 2018). - Wolf, L., et al. (2011). Automatic paleographic exploration of genizah manuscripts. In Fischer, F. (ed),
Kodikologie und Paläographie im Digitalen Zeitalter 2 – Codicology and Palaeography in the Digital Age 2. Norderstedt: Books on Demand, 157–179,
http://kups.ub.uni-koeln.de/4348/ (accessed 24 April 2018).